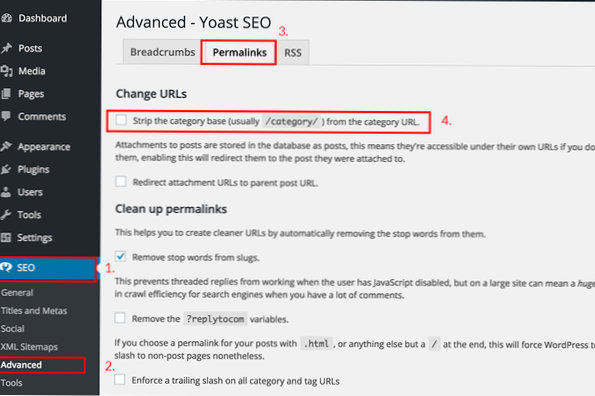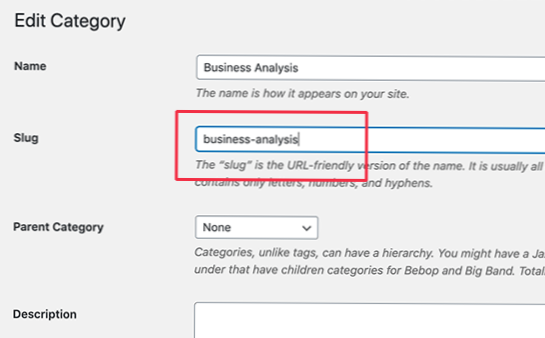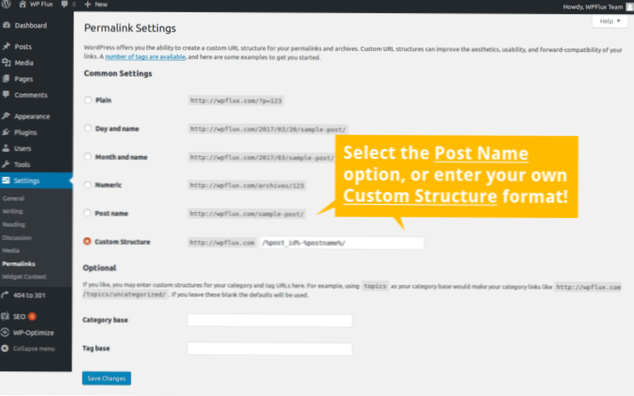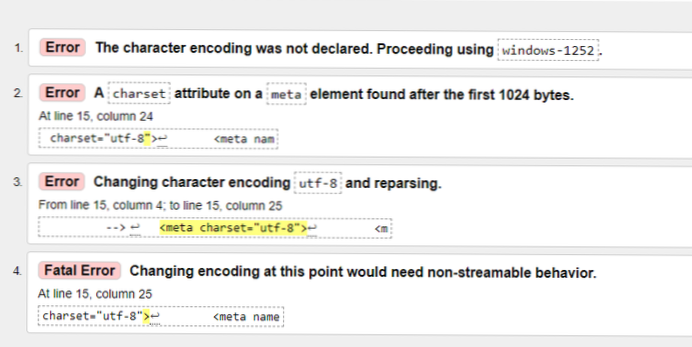
- Jak pozbyć się błędu UTF-8??
- Co to jest błąd UTF8??
- Jak zmienić kodowanie na UTF-8??
- Jak jest przechowywany UTF8??
- Jak rozwiązać problemy z Unicode??
- Jakie znaki nie są dozwolone w UTF-8??
- Co oznacza UTF-8 w HTML?
- Dlaczego UTF-8 zastąpił ascii?
- Czy UTF-8 jest taki sam jak Ascii?
- Jaka jest różnica między ANSI a UTF-8??
- Dlaczego używany jest kod UTF-8??
- Co oznacza UTF-8??
Jak pozbyć się błędu UTF-8??
2 odpowiedzi
- użyj zestawu znaków, który zaakceptuje dowolny bajt, taki jak iso-8859-15 znany również jako latin9.
- jeśli wyjście powinno być utf-8, ale zawiera błędy, użyj error=ignore -> po cichu usuwa znaki inne niż utf-8 lub błędy=zamień -> zastępuje znaki inne niż utf-8 znacznikiem zastępczym (zwykle ? )
Co to jest błąd UTF8??
UTF-8 to dominujący format kodowania znaków w sieci WWW. Ten błąd występuje, ponieważ używane oprogramowanie zapisuje plik w innym typie kodowania, takim jak ISO-8859, zamiast UTF-8. Istnieją różne rozwiązania, których możesz użyć, aby zmienić plik na kodowanie UTF-8.
Jak zmienić kodowanie na UTF-8??
Kliknij Narzędzia, a następnie wybierz Opcje internetowe. Przejdź do zakładki Kodowanie. Z listy rozwijanej Zapisz ten dokument jako: wybierz Unicode (UTF-8). Kliknij OK.
Jak jest przechowywany UTF8??
Gdy oprogramowanie czytające UTF-8 natrafi na bajt zaczynający się od 1, zlicza ile następuje 1 przed napotkaniem 0. ... Tak więc bajt postaci 110xxxxx mówi, że pierwsze pięć bitów znaku Unicode jest przechowywanych na końcu tego bajtu, a reszta bitów znajduje się w następnym bajcie.
Jak rozwiązać problemy z Unicode??
Pierwszym krokiem do rozwiązania problemu Unicode jest zaprzestanie myślenia o typie< „str”> jako przechowywanie ciągów (czyli ciągów znaków czytelnych dla człowieka, a.k.za. tekst). Zamiast tego zacznij myśleć o typie< „str”> jako pojemnik na bajty.
Jakie znaki nie są dozwolone w UTF-8??
Zwróć uwagę, że znak kolejności bajtów (BOM) U+FEFF, czyli spacja no-break o zerowej szerokości (ZWNBSP), nie może pojawić się w postaci niezakodowanej w UTF-8 — bajty 0xFF i 0xFE nie są dozwolone w prawidłowym UTF-8. Zakodowany ZWNBSP może pojawić się w pliku UTF-8 jako 0xEF 0xBB 0xBF, ale BOM jest całkowicie zbędny w UTF-8.
Co oznacza UTF-8 w HTML?
charset=UTF-8 oznacza zestaw znaków = format transformacji Unicode-8. Jest to oktetowe (8-bitowe) bezstratne kodowanie znaków Unicode. Powinny one rzucić więcej światła na zrozumienie w tworzeniu stron internetowych i skryptach.
Dlaczego UTF-8 zastąpił ascii?
UTF-8 zastąpił ASCII, ponieważ zawierał więcej znaków niż ASCII, który jest ograniczony do 128 znaków.
Czy UTF-8 jest taki sam jak Ascii?
W przypadku znaków reprezentowanych przez 7-bitowe kody znaków ASCII reprezentacja UTF-8 jest dokładnie równoważna ASCII, umożliwiając przezroczystą migrację w obie strony. Inne znaki Unicode są reprezentowane w UTF-8 przez sekwencje do 6 bajtów, chociaż większość znaków zachodnioeuropejskich wymaga tylko 2 bajtów3.
Jaka jest różnica między ANSI a UTF-8??
ANSI i UTF-8 to dwa schematy kodowania znaków, które są szeroko stosowane w tym czy innym momencie. Główną różnicą między nimi jest użycie, ponieważ UTF-8 prawie zastąpił ANSI jako wybrany schemat kodowania. ... Ponieważ ANSI używa tylko jednego bajtu lub 8 bitów, może reprezentować maksymalnie 256 znaków.
Dlaczego używany jest kod UTF-8??
Dlaczego warto używać UTF-8?? Strona HTML może mieć tylko jedno kodowanie. Nie możesz zakodować różnych części dokumentu w różnych kodowaniach. Kodowanie oparte na Unicode, takie jak UTF-8, może obsługiwać wiele języków i może pomieścić strony i formularze w dowolnej kombinacji tych języków.
Co oznacza UTF-8??
Podstawy UTF-8. UTF-8 (Unicode Transformation-8-bit) to kodowanie zdefiniowane przez Międzynarodową Organizację Normalizacyjną (ISO) w ISO 10646. Może reprezentować do 2 097 152 punktów kodowych (2 ^ 21), więcej niż wystarczająco, aby pokryć obecne 1 112 064 punkty kodowe Unicode.